We are all on the same page with churn, that a high churn rate could adversely affect profits and impede growth. On the strategy side, we have long speculated what might be the reason for our customers to leave, and tried to adjust our strategy to adjust and balance based on our “educated and qualitative speculations” in order to reduce the churn rate.
There are in general two approaches to reducing the churn rate.
Maachine learning can guide us to make great decisions with both approaches, I will demonstrate this with a smaple telco dataset.

There are 21 categories in this dataset, including the following data points. 'customerID', 'gender', 'SeniorCitizen', 'Partner', 'Dependents', 'tenure', 'PhoneService', 'MultipleLines', 'InternetService', 'OnlineSecurity', 'OnlineBackup', 'DeviceProtection', 'TechSupport', 'StreamingTV', 'StreamingMovies', 'Contract', 'PaperlessBilling', 'PaymentMethod', 'MonthlyCharges', 'TotalCharges', and 'Churn'.
Using the random forest classification method, we are able to build a model to predict at 89% accuracy which customers are likely churn. But also as important, we are doing well in the errors we are making as shown in the confusion matrix.
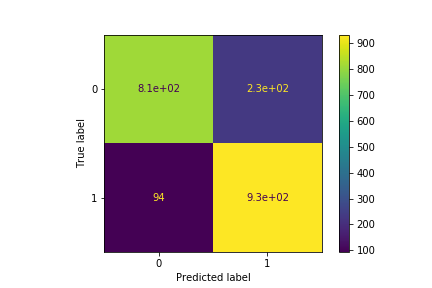
We only have 94 type 2 erros comparing to 232 type 1 errors, which means we are edging on the side of caution with our predictions. It is much better to send a discount to a customer who are not actually churning, then to miss the chance to save a customer who actually is.
In the long run, we want to identify which factors are important when it comes to churning and machine learning is set up to help with it too.
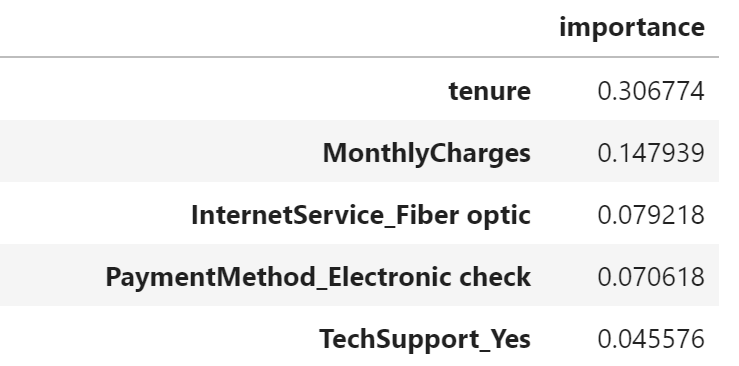
No surprise that Tenure is an important predictor, as well as monthly charge. One thing to note is that we shouldn't blindly follow the results from our model, but rather apply our business logic and analysis with this serving as the baseline for our improvement decisions.